News:
- NEW! Challenge Ranking tables.. (29-9-24)
- Test set labels (ground truth) now available. (19-3-24)
- Test set released! (see below). (25-2-24)
- Deadline for submission of results extended to March 1st. (24-2-24)
- TAUKADIAL Challenge announced! (25-1-24)
TAUKADIAL: Speech-Based Cognitive Assessment in Chinese and English
Cognitive problems, such as memory loss, speech and language impairment, and reasoning difficulties, occur frequently among older adults and often precede the onset of dementia syndromes. Due to the high prevalence of dementia worldwide, research into cognitive impairment for the purposes of dementia prevention and early detection has become a priority in healthcare. There is a need for cost-effective and scalable methods for assessment of cognition and detection of impairment, from its most subtle forms to severe manifestations of dementia. Speech is an easily collectable behavioural signal which reflects cognitive function, and therefore could potentially serve as a digital biomarker of cognitive function, presenting a unique opportunity for application of speech technology. While most studies to date have focused on English speech data, the TAUKADIAL Challenge aims to explore speech as a marker of cognition in a global health context, providing data from two major languages, namely, Chinese and English. The TAUKADIAL Challenge's tasks will focus on prediction of cognitive test scores and diagnosis of mild cognitive impairment (MCI) in older speakers of Chinese and English, using samples of connected speech. We expect that approaches that are language independent will be favoured. This INTERSPEECH Challenge will bring together members of the speech, signal processing, machine learning, natural language processing and biomedical research communities, enabling them to test existing methods or develop novel approaches on a new shared standardised dataset which will remain available to the community for future research and replication of results.
How to participate
To register for the TAUKADIAL Challenge and gain access to the TAUKADIAL dataset, please email taukadial2024@ed.ac.uk with your contact information and affiliation. Full access to the dataset will be provided through DementiaBank membership. To become a member, please include in your email to taukadial2024@ed.ac.uk a general statement of how you plan to use the data, with a specific mention to the TAUKADIAL Challenge. If you are a student, please ask your supervisor to join DementiaBank as well.
The TAUKADIAL challenge encompasses the following tasks:
- a classification task, where participants will create models to distinguish healthy control speech from MCI speech, and
- a cognitive test score prediction (regression) task, where you create a model to infer the subject's Mini Mental Status Examination (MMSE) or Montreal Cognitive Assessment (MoCA) scores based on connected (spontaneous) speech data;
You may choose to do one or both of these tasks. You will be provided with access to a training set (see relevant section below), and two weeks prior to the paper submission deadline you will be provided with test sets on which you can test your models.
You may send up to five sets of results to us for scoring for each task. You are required to submit all your attempts together, in separate files named: taukadial_results_task1_attempt1.txt, taukadial_results_task2_attemp1.txt (or one of these, should you choose not to enter both tasks). These must contain the IDs of the test files and your model's predictions. You will be provided with README files in the test sets archives with further details. The test sets will contain README.md files with further details.
As the broad scientific goal of TAUKADIAL is to gain insight into the nature of the relationship between speech and cognitive function across different languages, we encourage you to upload a paper describing your approaches and results to a pre-print repository such as arXiv or medRxiv, and to submit your paper to INTERSPEECH, regardless of your position in the rank. Note, however, that for INTERSPEECH submissions, "online posting of any version* of the paper under submission is forbidden during an anonymity period starting one month prior to the Interspeech submission deadline and up to the moment the accept/reject decisions are announced" . So, any submissions to pre-print repositories should comply with this policy.
We also encourage you to share your code through a publicly accessible repository, if possible using a literate programming "notebook" environment such as R Markdown or Jupyter Notebook.
The data set
The training data set consists of spontaneous speech samples corresponding to audio recordings of picture descriptions produced by cognitively normal subjects and patients with MCI. The participants are speakers of English or Chinese. The test set consists of speech descriptions by different participants in one of these two languages.The data set has been balanced with respect to age and sex in order to eliminate potential confunding and bias. We employed a propensity score approach to matching (Rosenbaum & Rubin, 1983; Rubin 1973; Ho et al. 2007). It contains both Chinese and English audio files with recordings of picture descriptions. There are 3 picture descriptions per participant. The file names are in the following format taukdial-MMM-N.wav, where MMM is a random integer, and N is an integer between 1 and 3 (inclusive) indicating the picture description contained in the recording. Note that the three pictured used in the English descriptions are different from the three pictures described by the Chinese speakers.
Please email taukadial2024@ed.ac.uk to get access to the training set,
as described above.
Test set
The test data
are now
available at DementiaBank (you will need your login details to
download it). Please
email taukadial2024@ed.ac.uk
for instructions on how to submit your model's predictions.
The ground truth for test data is also available.
Modelling and Evaluation
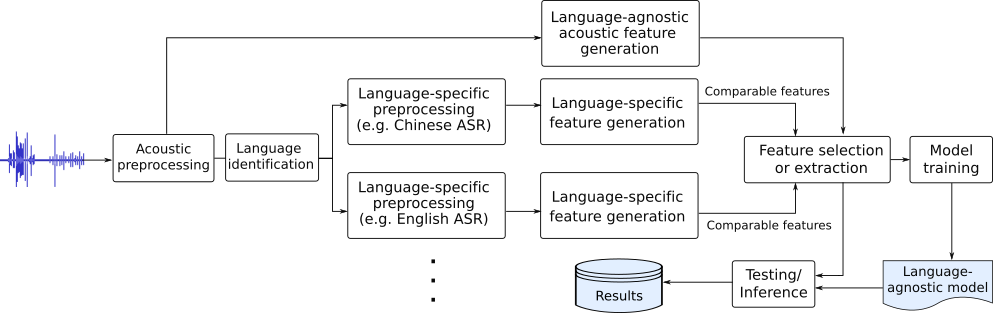
As the goal of the TAUKADIAL Challenge is to explore models that generalise across languages, we encourage participants to develop models encompassing features extracted from both languages. A possible architecture for a classification or regression system for this challenge could be as shown below, where comparable features extracted from both languages are combined into a single predictive model:
Evaluation
Task 1: MCI classification will be evaluated through specificity (\(\sigma\)), sensitivity (\(\rho\)) and \(F_1\) scores for the MCI category. These metrics will be computed as follows: \[ \displaystyle \operatorname{\sigma} = { \frac { TN }{TN + FP} }, \] and \[ \displaystyle \operatorname {F_1} = { \frac { 2 \pi \rho }{\pi + \rho} } \] where \[ \displaystyle \operatorname {\pi} = { \frac { TP }{TP + FP} }, \] \[ \displaystyle \operatorname {\rho} = { \frac { TP }{TP + FN} }, \] N is the number of patients, TP is the number of true positives, TN is the number of true negatives, FP is the number of false positives and FN the number of false negatives.
The balanced accuracy metric (unweighted average recall, UAR) will be used for the overall ranking of this task's results: \[ \displaystyle \operatorname {UAR} = {\frac { \sigma + \rho }{2} } \]
Task 2 (MMSE prediction) will be evaluated using the coefficient of determination: \[ \displaystyle \operatorname {R^2} =1 - \frac {\sum_{i=1}^N(\hat{y}_{i} - y_{i})^2} {\sum_{i=1}^N(\hat{y}_{i} - \bar{y})^2} \] and the root mean squared error: \[ \displaystyle \operatorname {RMSE} ={\sqrt {\frac {\sum _{i=1}^{N}({\hat {y}}_{i}-y_{i})^{2}}{N}}} \] where \(\hat{y}\) is the predicted MMSE score, \(y\) is the patient's actual MMSE score, and \(\bar{y}\) is the mean score.
When more than one attempt is submitted for scoring against the test set, all results should be considered (not only the best result overall) and reported in the paper.
The ranking of submissions will be done based on accuracy scores for the classification task (task 1), and on RMSE scores for the MMSE score regression task (task 2).TAUKADIAL Description Paper and Baseline Results
A paper describing the TAUKADIAL Grand Challenge and its dataset more fully, along with a basic set of baseline results will be shared with the registered TAUKADIAL Challenge participants, and eventually submitted to INTERSPEECH. Papers submitted to this Challenge using the TAUKADIAL dataset should cite this paper as follows
- Luz S, Garcia SdLF, Haider F, Fromm D, MacWhinney B, Lanzi, A, Chang, YN,
Chou CJ and Liu YC. Connected Speech-Based Cognitive Assessment in
Chinese and English
. Proceedings of Interspeech, pp 947--951, Kos,
Greece, 2024. (Paper available at
ISCA
Archive and
arXiv)
[BibTeX]
We encourage you to submit papers describing your approaches to the
tasks set here to https://arxiv.org/,
after the INTERSPEECH anonymity period, and to share your code
through open-source repositories. Please note that the intellectual
property (IP) related to your submission is not transferred to the
challenge organizers, i.e., if code is shared/submitted, the
participants remain the owners of their code. When the code is made
publicly available, an appropriate license should be added.
Important Dates
- 25th January: TAUKADIAL Challenge announced; Call for Participation Published
- 20th February: registration deadline; please email taukadial2024@ed.ac.uk to register for the challenge and receive the training and sample sets.
- 1 March: deadline for submission of results
- INTERSPEECH Paper Submission Deadline: 2 March 2024
- INTERSPEECH paper update deadline: 11 March 2024
- INTERSPEECH paper acceptance notification: 6 June 2024.
- TAUKADIAL Session at INTERSPEECH: TBD (between 2 and 7 September 2024)
Paper Submission
See Call for Papers and Author resources at the INTERSPEECH 2024 web site for instructions.
References
- de la Fuente Garcia S, Ritchie C, Luz S. Artificial Intelligence, Speech, and Language Processing Approaches to Monitoring Alzheimer’s Disease: A Systematic Review. Journal of Alzheimer's Disease. 2020:1-27. DOI: 10.3233/JAD-200888
- Luz S, Haider F, Fromm D, MacWhinney B, (eds.). Alzheimer’s Dementia Recognition Through Spontaneous Speech. Lausanne, Switzerland: Frontiers Media S.A., 2021. 258 p. DOI: 10.3389/978-2-88971-854-2
- Rosenbaum PR, Rubin DB. 1983. The Central Role of the Propensity Score in Observational Studies for Causal Effects. Biometrika 70 (1): 41–55. DOI: 10.1093/biomet/70.1.41
- Rubin DB 1973. Matching to Remove Bias in Observational Studies. Biometrics 29 (1): 159. DOI: 10.2307/2529684.
- Ho DE, Kosuke I, King G, Stuart EA. 2007. Matching as Nonparametric Preprocessing for Reducing Model Dependence in Parametric Causal Inference. Political Analysis 15 (3): 199–236.
Organizers
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|



|